Intro – Exploring the Impressive Mistral 7B Model
The Mistral 7B model, released by Mistral AI, is a groundbreaking 7 billion parameter model that has caught the attention of many in the AI community. This foundational model stands out for its exceptional performance and unique architecture.
Understanding the Mistral 7B Model
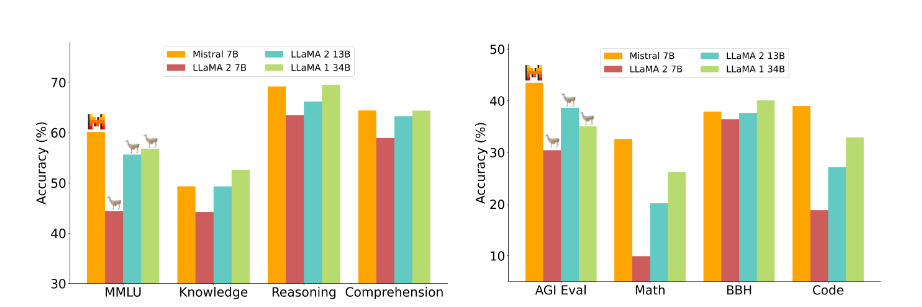
The Mistral 7B model differs from other models we have seen before. Despite its small size, it outperforms larger models like Gamma 2 13B and Llama 1 34B in various benchmarks. Although its primary focus is on English tasks, it also excels in coding abilities. As noted on their website it’s licensed under Apache 2.0(use it for commercial license). As of the date of this publication, it has 17,794 Downloads on huggingface.

Features and Performance
The Mistral 7B model utilizes grouped query attention for faster inference and sliding window attention for longer response sequences. With its impressive performance, it is optimal for low-latency text summarization, classification, text completion, and code completion.
Model: Fine-Tuned Instruct Model
Mistral AI has released fine-tuned instruct model. It demonstrates remarkable performance on benchmarks and real-world tests, surpassing the previous 7 billion and even 13 billion models in several tasks and it is trained on a variety of publicly available conversation datasets.
from transformers import AutoModelForCausalLM, AutoTokenizer
device = "cuda" # the device to load the model onto
model = AutoModelForCausalLM.from_pretrained("mistralai/Mistral-7B-Instruct-v0.1")
tokenizer = AutoTokenizer.from_pretrained("mistralai/Mistral-7B-Instruct-v0.1")
messages = [
{"role": "user", "content": "What is your favourite condiment?"},
{"role": "assistant", "content": "Well, I'm quite partial to a good squeeze of fresh lemon juice. It adds just the right amount of zesty flavour to whatever I'm cooking up in the kitchen!"},
{"role": "user", "content": "Do you have mayonnaise recipes?"}
]
encodeds = tokenizer.apply_chat_template(messages, return_tensors="pt")
model_inputs = encodeds.to(device)
model.to(device)
generated_ids = model.generate(model_inputs, max_new_tokens=1000, do_sample=True)
decoded = tokenizer.batch_decode(generated_ids)
print(decoded[0])Integration and Frameworks
Mistral AI provides instructions on how to use the Mistral 7B model with the Hugging Face Transformer package. Below is the test on the perplexity. The results are insane and fast. It has trained to output program codes too.
How to install Mistral 7B locally
Ollama is a tool that allows users to work with large language models locally on their laptops. It can be used to run Llama 2, Code Llama, and other models, as well as customize and create new models. Ollama is available for macOS, and Linux. To install Ollama, users can follow these steps:
- Visit the Ollama website at https://ollama.ai/ and click on the “Download” button.
- Download the Ollama app.
- Open the downloaded file and run the app inside.
- Once the installation is complete, users should see the Ollama app in their menu bar.
- Visit https://github.com/jmorganca/ollama and check the Model library. Here we want to install Mistral. So copy ollama run mistral
- Run it locally on the terminal. Once it is installed you can start asking questions.
Alternatively, users can install Ollama on Linux using the following command: curl https://ollama.ai/install.sh | sh.I
It’s worth noting that Ollama is designed to run locally on a user’s laptop, but it is also possible to run it on a cloud service providers such as DigitalOcean, AWS, or any other online hosting.
Limitations and Uncensored Nature
While the Mistral 7B model offers impressive capabilities, it is important to note that it currently lacks moderation mechanisms. As a result, it is considered an uncensored model without any censorship filters. Users should be aware of this when utilizing the model.
Model Accessibility and Formats
Mistral AI has made the Mistral 7B model accessible for commercial purposes under the Apache 2.0 license. The model weights are available in both TPtq and GGUF formats, making it convenient for users to incorporate the model into their own code bases.
Language Understanding and Writing Abilities
The Mistral 7B model demonstrates excellent language understanding abilities. It successfully answers complex questions and provides step-by-step explanations. It even surpasses smaller 7 billion models in language understanding tasks.
Impressive Coding Abilities
One of the highlights of the Mistral 7B model is its coding ability. It can generate Python, C, Java, and HTML code for a variety of tasks, from simple functions to more complex tasks. The model’s generated code demonstrates a high level of accuracy and functionality.
Political Questions and Responses
Interestingly, the Mistral 7B model provides responses to political questions without stating its own political opinions. It offers balanced and neutral perspectives, providing information without bias. This distinguishes it from other models that tend to avoid political discussions.
💁 Check out our other articles😃
Comprehensive Guide to Marketing Any Digital Product using AI Prompts
Generate class plan for teachers using AI prompts in ChatGPT
Conclusion
In conclusion, the Mistral 7B model is an impressive achievement in the field of AI. Its exceptional performance, unique architecture, and remarkable coding and language understanding abilities make it a valuable tool for various applications. Whether it’s text summarization, coding, or language tasks, the Mistral 7B model proves to be a powerful and versatile option. With its accessibility and integration possibilities, it opens up new opportunities for AI research and development.